 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHydraPrompt: An Adaptive and Asymmetric Framework of Vision-Language Models for Synthetic Image Detection
May 26, 2026The rapid evolution of generative models has precipitated a proliferation of fabricated content, posing significant challenges to existing Synthetic Image Detection (SID) methods. Capitalizing on advancements in vision-language models (e.g., CLIP), recent attempts have leveraged learnable textual prompts to identify synthetic images. However, they still leverage static prompt as a fixed boundary for real and fake images, failing to adapt to the varying types of forgery that emerge during inference. To overcome this issue, we propose **HydraPrompt**, an asymmetric prompting framework that dynamically adjusts the category centers by aligning with fine-grained image cues. Specifically, we propose an Asymmetric Prompt Adapter (**APA**): (1) for authentic category, we introduce a single set of prompts to capture the consistent representative patterns, which serves as a unified anchor for real content. While (2) for fake category, we construct sample-adaptive prompts that specialize in capturing diverse cues from different samples, enabling adaptive modeling of forgery image variations. To increase pronounced discriminability within different synthetic images, we further introduce a Conditional Supervised Contrastive (**CSC**) objective, which compacts the authentic representations while capturing fine-grained forgery clues. Extensive experiments on popular SID benchmarks demonstrate the state-of-the-art performance of our framework.
Reduce the Artifacts Bias for More Generalizable AI-Generated Image Detection
May 14, 2026As the misuse of AI-generated images grows, generalizable image detection techniques are urgently needed. Recent state-of-the-art (SOTA) methods adopt aligned training datasets to reduce content, size, and format biases, empowering models to capture robust forgery cues. A common strategy is to employ reconstruction techniques, e.g., VAE and DDIM, which show remarkable results in diffusion-based methods. However, such reconstruction-based approaches typically introduce limited and homogeneous artifacts, which cannot fully capture diverse generative patterns, such as GAN-based methods. To complement reconstruction-based fake images with aligned yet diverse artifact patterns, we propose a GAN-based upsampling approach that mimics GAN-generated fake patterns while preserving content, size, and format alignment. This naturally results in two aligned but distinct types of fake images. However, due to the domain shift between reconstruction-based and upsampling-based fake images, direct mixed training causes suboptimal results, where one domain disrupts feature learning of the other. Accordingly, we propose a Separate Expert Fusion (SEF) framework to extract complementary artifact information and reduce inter-domain interference. We first train domain-specific experts via LoRA adaptation on a frozen foundational model, then conduct decoupled fusion with a gating network to adaptively combine expert features while retaining their specialized knowledge. Rather than merely benefiting GAN-generated image detection, this design introduces diverse and complementary artifact patterns that enable SEF to learn a more robust decision boundary and improve generalization across broader generative methods. Extensive experiments demonstrate that our method yields strong results across 13 diverse benchmarks. Codes are released at: https://github.com/liyih/SEF_AIGC_detection.
CTForensics: A Comprehensive Dataset and Method for AI-Generated CT Image Detection
Mar 02, 2026With the rapid development of generative AI in medical imaging, synthetic Computed Tomography (CT) images have demonstrated great potential in applications such as data augmentation and clinical diagnosis, but they also introduce serious security risks. Despite the increasing security concerns, existing studies on CT forgery detection are still limited and fail to adequately address real-world challenges. These limitations are mainly reflected in two aspects: the absence of datasets that can effectively evaluate model generalization to reflect the real-world application requirements, and the reliance on detection methods designed for natural images that are insensitive to CT-specific forgery artifacts. In this view, we propose CTForensics, a comprehensive dataset designed to systematically evaluate the generalization capability of CT forgery detection methods, which includes ten diverse CT generative methods. Moreover, we introduce the Enhanced Spatial-Frequency CT Forgery Detector (ESF-CTFD), an efficient CNN-based neural network that captures forgery cues across the wavelet, spatial, and frequency domains. First, it transforms the input CT image into three scales and extracts features at each scale via the Wavelet-Enhanced Central Stem. Then, starting from the largest-scale features, the Spatial Process Block gradually performs feature fusion with the smaller-scale ones. Finally, the Frequency Process Block learns frequency-domain information for predicting the final results. Experiments demonstrate that ESF-CTFD consistently outperforms existing methods and exhibits superior generalization across different CT generative models.
VideoVeritas: AI-Generated Video Detection via Perception Pretext Reinforcement Learning
Feb 09, 2026The growing capability of video generation poses escalating security risks, making reliable detection increasingly essential. In this paper, we introduce VideoVeritas, a framework that integrates fine-grained perception and fact-based reasoning. We observe that while current multi-modal large language models (MLLMs) exhibit strong reasoning capacity, their granular perception ability remains limited. To mitigate this, we introduce Joint Preference Alignment and Perception Pretext Reinforcement Learning (PPRL). Specifically, rather than directly optimizing for detection task, we adopt general spatiotemporal grounding and self-supervised object counting in the RL stage, enhancing detection performance with simple perception pretext tasks. To facilitate robust evaluation, we further introduce MintVid, a light yet high-quality dataset containing 3K videos from 9 state-of-the-art generators, along with a real-world collected subset that has factual errors in content. Experimental results demonstrate that existing methods tend to bias towards either superficial reasoning or mechanical analysis, while VideoVeritas achieves more balanced performance across diverse benchmarks.
One Ring to Rule Them All: Unifying Group-Based RL via Dynamic Power-Mean Geometry
Jan 30, 2026Group-based reinforcement learning has evolved from the arithmetic mean of GRPO to the geometric mean of GMPO. While GMPO improves stability by constraining a conservative objective, it shares a fundamental limitation with GRPO: reliance on a fixed aggregation geometry that ignores the evolving and heterogeneous nature of each trajectory. In this work, we unify these approaches under Power-Mean Policy Optimization (PMPO), a generalized framework that parameterizes the aggregation geometry via the power-mean geometry exponent p. Within this framework, GRPO and GMPO are recovered as special cases. Theoretically, we demonstrate that adjusting p modulates the concentration of gradient updates, effectively reweighting tokens based on their advantage contribution. To determine p adaptively, we introduce a Clip-aware Effective Sample Size (ESS) mechanism. Specifically, we propose a deterministic rule that maps a trajectory clipping fraction to a target ESS. Then, we solve for the specific p to align the trajectory induced ESS with this target one. This allows PMPO to dynamically transition between the aggressive arithmetic mean for reliable trajectories and the conservative geometric mean for unstable ones. Experiments on multiple mathematical reasoning benchmarks demonstrate that PMPO outperforms strong baselines.
Veritas: Generalizable Deepfake Detection via Pattern-Aware Reasoning
Aug 28, 2025



Deepfake detection remains a formidable challenge due to the complex and evolving nature of fake content in real-world scenarios. However, existing academic benchmarks suffer from severe discrepancies from industrial practice, typically featuring homogeneous training sources and low-quality testing images, which hinder the practical deployments of current detectors. To mitigate this gap, we introduce HydraFake, a dataset that simulates real-world challenges with hierarchical generalization testing. Specifically, HydraFake involves diversified deepfake techniques and in-the-wild forgeries, along with rigorous training and evaluation protocol, covering unseen model architectures, emerging forgery techniques and novel data domains. Building on this resource, we propose Veritas, a multi-modal large language model (MLLM) based deepfake detector. Different from vanilla chain-of-thought (CoT), we introduce pattern-aware reasoning that involves critical reasoning patterns such as "planning" and "self-reflection" to emulate human forensic process. We further propose a two-stage training pipeline to seamlessly internalize such deepfake reasoning capacities into current MLLMs. Experiments on HydraFake dataset reveal that although previous detectors show great generalization on cross-model scenarios, they fall short on unseen forgeries and data domains. Our Veritas achieves significant gains across different OOD scenarios, and is capable of delivering transparent and faithful detection outputs.
Unleashing the Potential of Consistency Learning for Detecting and Grounding Multi-Modal Media Manipulation
Jun 06, 2025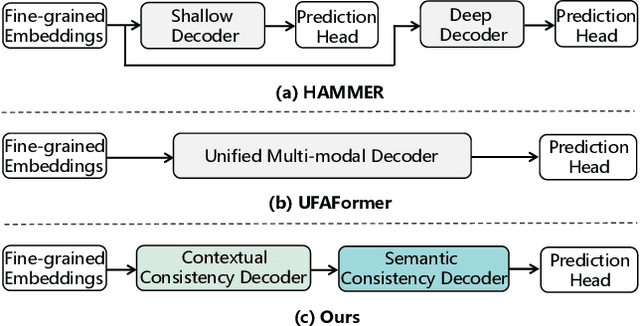
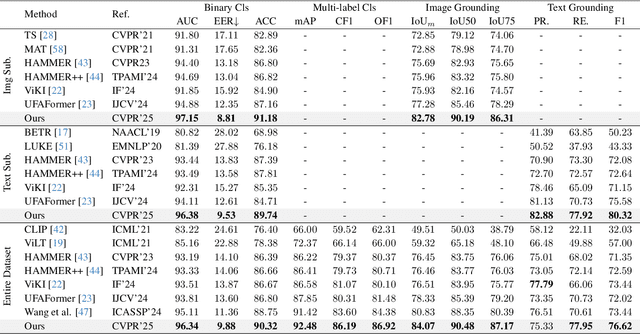
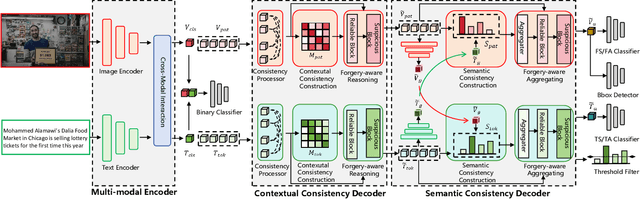
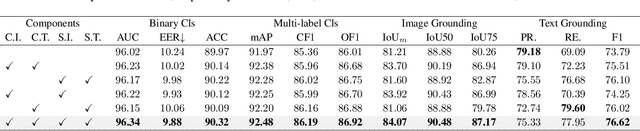
To tackle the threat of fake news, the task of detecting and grounding multi-modal media manipulation DGM4 has received increasing attention. However, most state-of-the-art methods fail to explore the fine-grained consistency within local content, usually resulting in an inadequate perception of detailed forgery and unreliable results. In this paper, we propose a novel approach named Contextual-Semantic Consistency Learning (CSCL) to enhance the fine-grained perception ability of forgery for DGM4. Two branches for image and text modalities are established, each of which contains two cascaded decoders, i.e., Contextual Consistency Decoder (CCD) and Semantic Consistency Decoder (SCD), to capture within-modality contextual consistency and across-modality semantic consistency, respectively. Both CCD and SCD adhere to the same criteria for capturing fine-grained forgery details. To be specific, each module first constructs consistency features by leveraging additional supervision from the heterogeneous information of each token pair. Then, the forgery-aware reasoning or aggregating is adopted to deeply seek forgery cues based on the consistency features. Extensive experiments on DGM4 datasets prove that CSCL achieves new state-of-the-art performance, especially for the results of grounding manipulated content. Codes and weights are avaliable at https://github.com/liyih/CSCL.
Recover and Match: Open-Vocabulary Multi-Label Recognition through Knowledge-Constrained Optimal Transport
Mar 19, 2025



Identifying multiple novel classes in an image, known as open-vocabulary multi-label recognition, is a challenging task in computer vision. Recent studies explore the transfer of powerful vision-language models such as CLIP. However, these approaches face two critical challenges: (1) The local semantics of CLIP are disrupted due to its global pre-training objectives, resulting in unreliable regional predictions. (2) The matching property between image regions and candidate labels has been neglected, relying instead on naive feature aggregation such as average pooling, which leads to spurious predictions from irrelevant regions. In this paper, we present RAM (Recover And Match), a novel framework that effectively addresses the above issues. To tackle the first problem, we propose Ladder Local Adapter (LLA) to enforce refocusing on local regions, recovering local semantics in a memory-friendly way. For the second issue, we propose Knowledge-Constrained Optimal Transport (KCOT) to suppress meaningless matching to non-GT labels by formulating the task as an optimal transport problem. As a result, RAM achieves state-of-the-art performance on various datasets from three distinct domains, and shows great potential to boost the existing methods. Code: https://github.com/EricTan7/RAM.
Make Your ViT-based Multi-view 3D Detectors Faster via Token Compression
Sep 01, 2024



Slow inference speed is one of the most crucial concerns for deploying multi-view 3D detectors to tasks with high real-time requirements like autonomous driving. Although many sparse query-based methods have already attempted to improve the efficiency of 3D detectors, they neglect to consider the backbone, especially when using Vision Transformers (ViT) for better performance. To tackle this problem, we explore the efficient ViT backbones for multi-view 3D detection via token compression and propose a simple yet effective method called TokenCompression3D (ToC3D). By leveraging history object queries as foreground priors of high quality, modeling 3D motion information in them, and interacting them with image tokens through the attention mechanism, ToC3D can effectively determine the magnitude of information densities of image tokens and segment the salient foreground tokens. With the introduced dynamic router design, ToC3D can weigh more computing resources to important foreground tokens while compressing the information loss, leading to a more efficient ViT-based multi-view 3D detector. Extensive results on the large-scale nuScenes dataset show that our method can nearly maintain the performance of recent SOTA with up to 30% inference speedup, and the improvements are consistent after scaling up the ViT and input resolution. The code will be made at https://github.com/DYZhang09/ToC3D.
SSPA: Split-and-Synthesize Prompting with Gated Alignments for Multi-Label Image Recognition
Jul 30, 2024



Multi-label image recognition is a fundamental task in computer vision. Recently, Vision-Language Models (VLMs) have made notable advancements in this area. However, previous methods fail to effectively leverage the rich knowledge in language models and often incorporate label semantics into visual features unidirectionally. To overcome these problems, we propose a Split-and-Synthesize Prompting with Gated Alignments (SSPA) framework to amplify the potential of VLMs. Specifically, we develop an in-context learning approach to associate the inherent knowledge from LLMs. Then we propose a novel Split-and-Synthesize Prompting (SSP) strategy to first model the generic knowledge and downstream label semantics individually and then aggregate them carefully through the quaternion network. Moreover, we present Gated Dual-Modal Alignments (GDMA) to bidirectionally interact visual and linguistic modalities while eliminating redundant cross-modal information, enabling more efficient region-level alignments. Rather than making the final prediction by a sharp manner in previous works, we propose a soft aggregator to jointly consider results from all image regions. With the help of flexible prompting and gated alignments, SSPA is generalizable to specific domains. Extensive experiments on nine datasets from three domains (i.e., natural, pedestrian attributes and remote sensing) demonstrate the state-of-the-art performance of SSPA. Further analyses verify the effectiveness of SSP and the interpretability of GDMA. The code will be made public.